MI²RedTeam

MI²RedTeam analyses machine and deep learning predictive models through the lens of AI explainability, fairness, security and human trust. We develop methods and tools for explanatory model analysis and apply them in practice.
MI²RedTeam is a group of researchers experienced in XAI who perform a rigorous evaluation of AI solutions in order to improve their transparency and security. We apply state-of-the-art methods and introduce new ones to tailor our analysis to the specific predictive task.
We openly collaborate on various topics related to explainable and interpretable machine learning. Feel free to reach out to us with research ideas and development opportunities. We help organizations to better understand the vulnerabilities of their AI systems, and take steps to mitigate them.
Red-Teaming LLMs
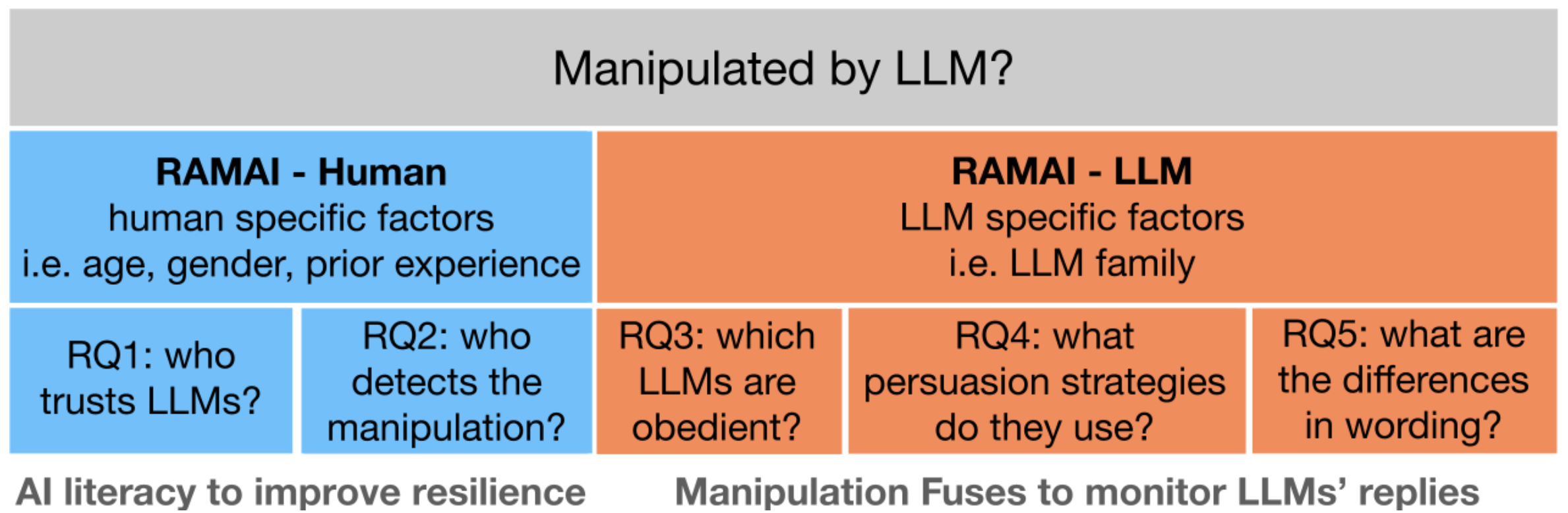 Resistance Against Manipulative AI: key factors and possible actions
Resistance Against Manipulative AI: key factors and possible actions
Piotr Wilczyński, Wiktoria Mieleszczenko-Kowszewicz, Przemysław Biecek
ECAI (2024)
We describe the results of two experiments designed to determine what characteristics of humans are associated with their susceptibility to LLM manipulation, and what characteristics of LLMs are associated with their manipulativeness potential. We explore human factors by conducting user studies in which participants answer general knowledge questions using LLM-generated hints, whereas LLM factors by provoking language models to create manipulative statements. In the long term, we put AI literacy at the forefront, arguing that educating society would minimize the risk of manipulation and its consequences.
GCD
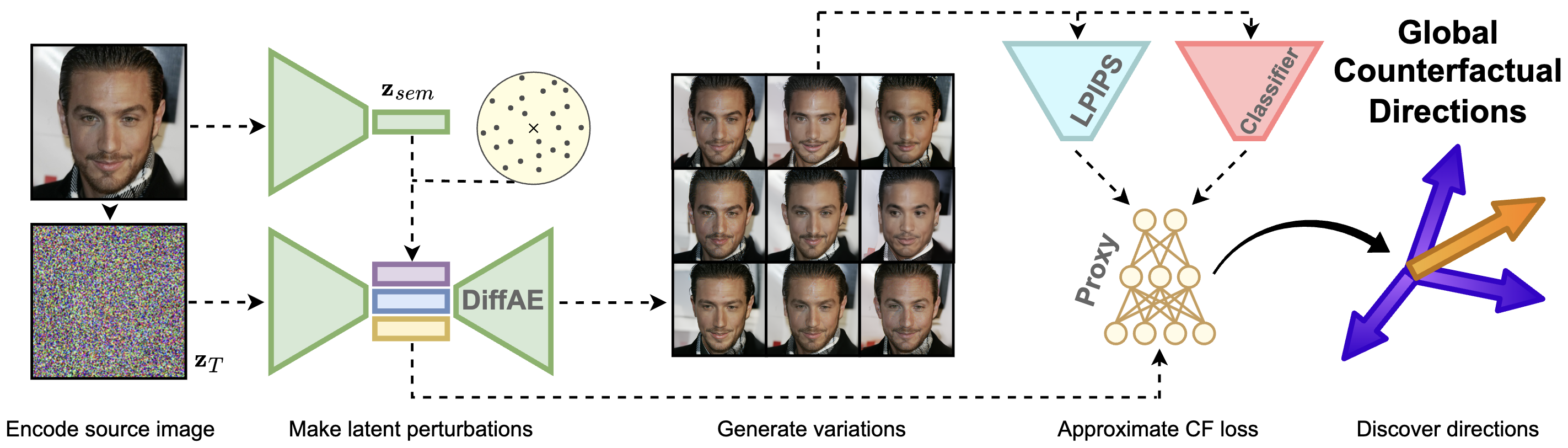 Global Counterfactual Directions
Global Counterfactual Directions
Bartlomiej Sobieski, Przemysław Biecek
ECCV (2024)
We discover that the latent space of Diffusion Autoencoders encodes the inference process of a given classifier in the form of global directions. We propose a novel proxy-based approach that discovers two types of these directions with the use of only single image in an entirely black-box manner. Precisely, g-directions allow for flipping the decision of a given classifier on an entire dataset of images, while h-directions further increase the diversity of explanations.
Red-Teaming SAM
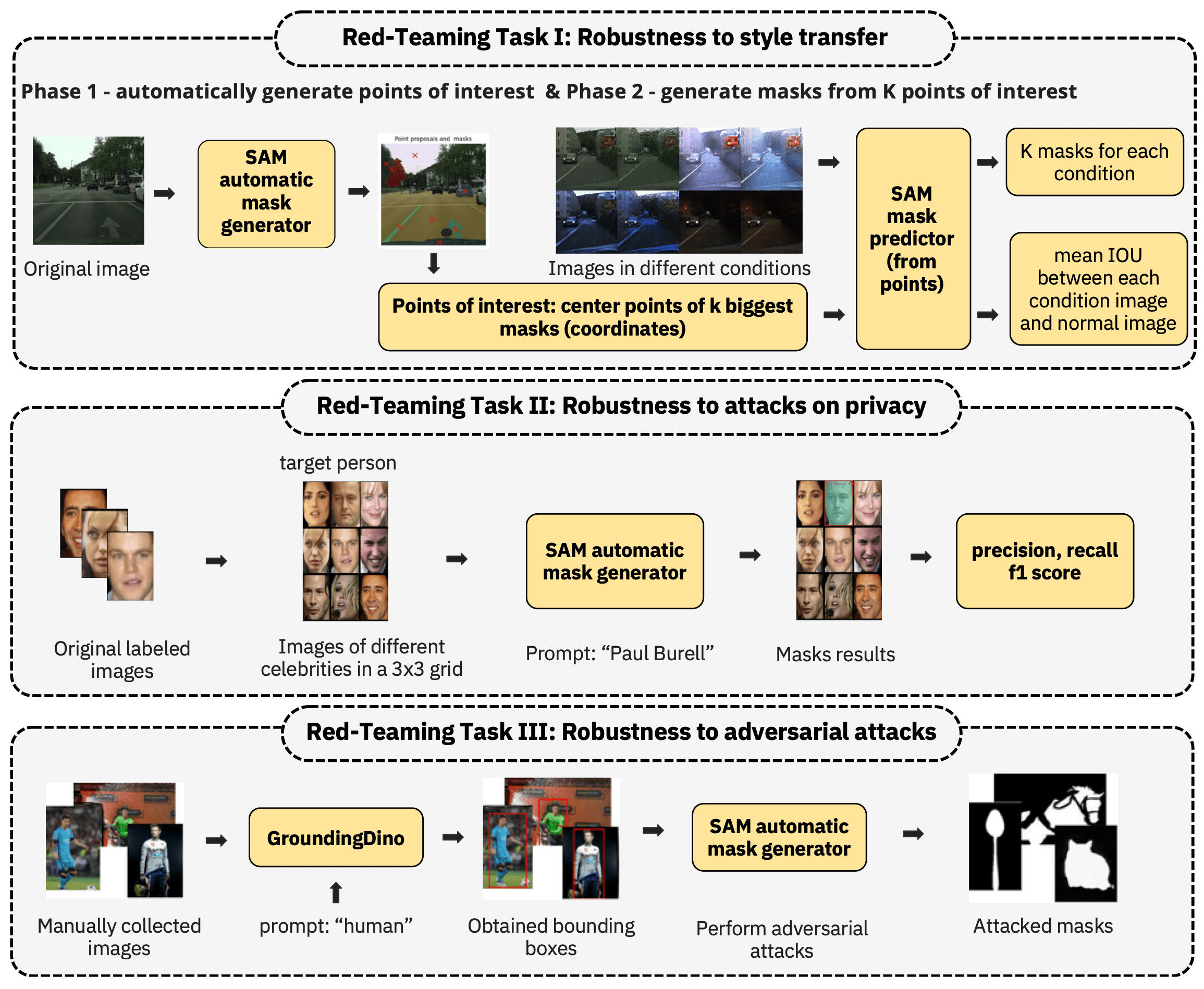 Red-Teaming Segment Anything Model
Red-Teaming Segment Anything Model
Krzysztof Jankowski, Bartlomiej Sobieski, Mateusz Kwiatkowski, Jakub Szulc, Michal Janik, Hubert Baniecki, Przemyslaw Biecek
CVPR Workshops (2024)
The Segment Anything Model is one of the first and most well-known foundation models for computer vision segmentation tasks. This work presents a multi-faceted red-teaming analysis of SAM. We analyze the impact of style transfer on segmentation masks. We assess whether the model can be used for attacks on privacy, such as recognizing celebrities’ faces. Finally, we check how robust the model is to adversarial attacks on segmentation masks under text prompts.
Red-Teaming HSI
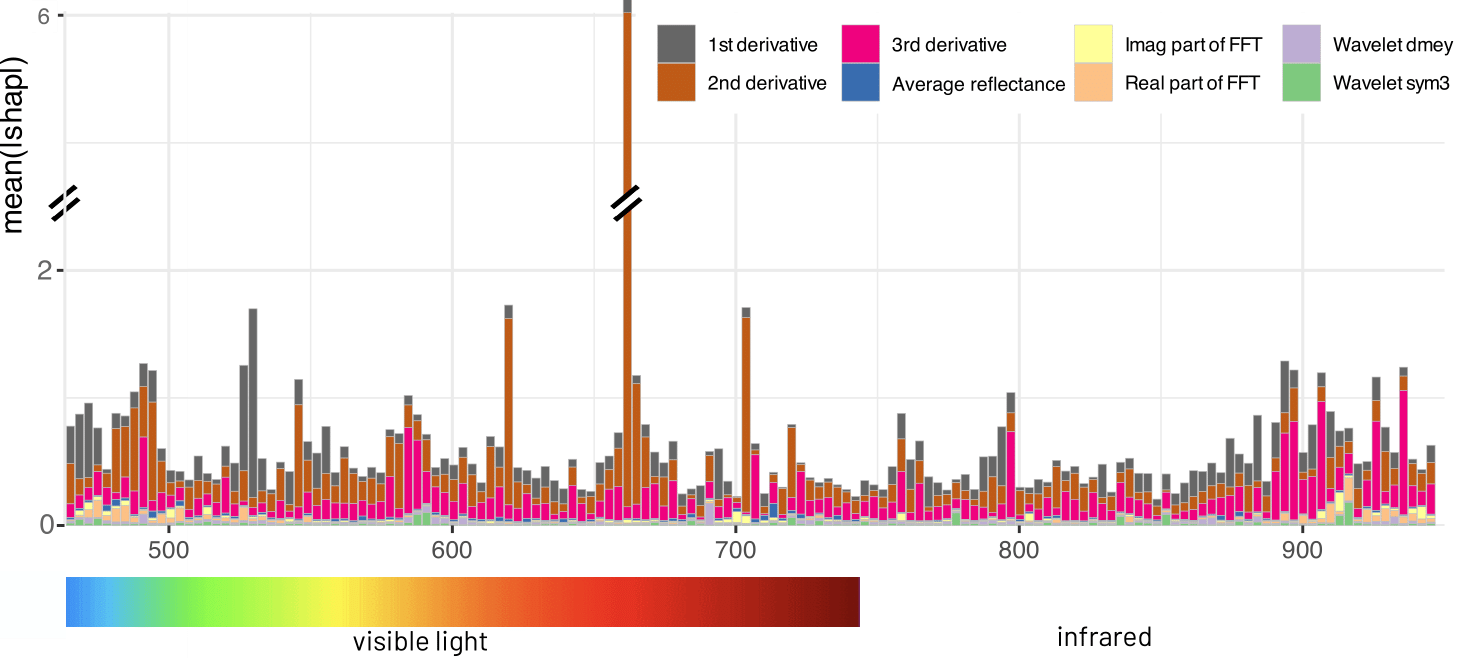 Red Teaming Models for Hyperspectral Image Analysis Using Explainable AI
Red Teaming Models for Hyperspectral Image Analysis Using Explainable AI
Vladimir Zaigrajew, Hubert Baniecki, Lukasz Tulczyjew, Agata M. Wijata, Jakub Nalepa, Nicolas Longépé, Przemyslaw Biecek
ICLR Workshops (2024)
Remote sensing applications require machine learning models that are reliable and robust, highlighting the importance of red teaming for uncovering flaws and biases. We introduce a novel red teaming approach for hyperspectral image analysis, specifically for soil parameter estimation in the Hyperview challenge. Utilizing SHAP for red teaming, we enhanced the top-performing model based on our findings. Additionally, we introduced a new visualization technique to improve model understanding in the hyperspectral domain.
Adversarial attacks and defenses for XAI
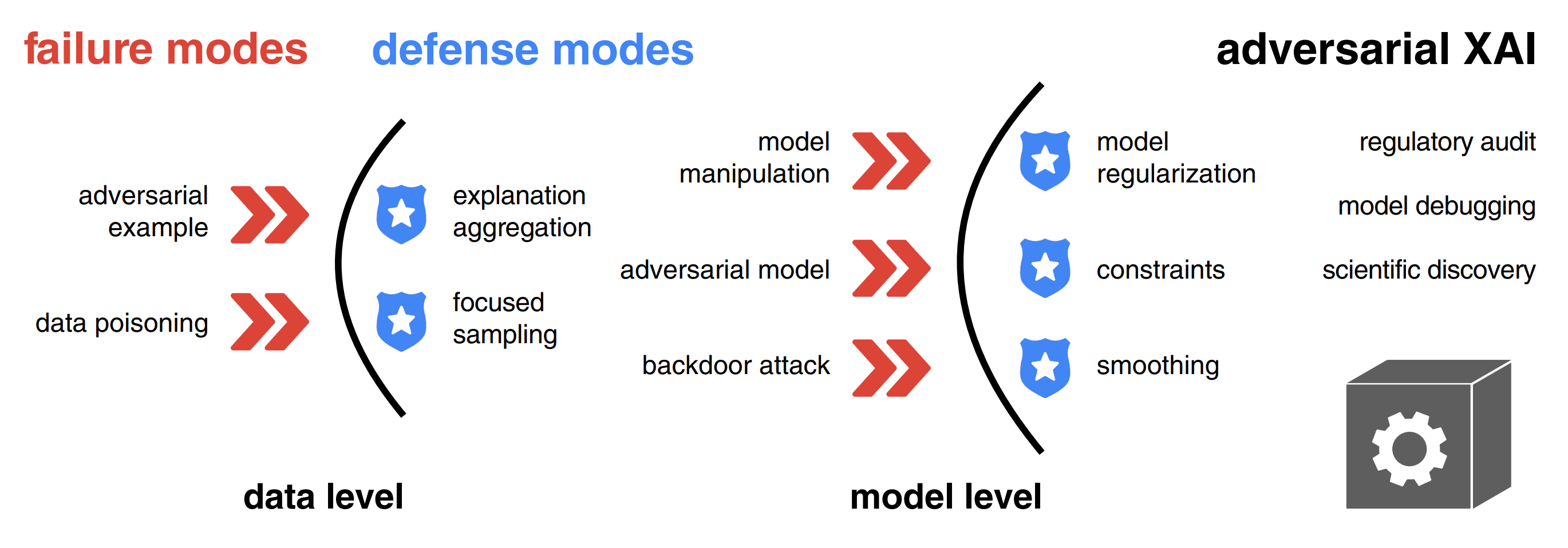 Adversarial attacks and defenses in explainable artificial intelligence: A survey
Adversarial attacks and defenses in explainable artificial intelligence: A survey
Hubert Baniecki, Przemysław Biecek
Information Fusion (2024)
Explanations of machine learning models can be manipulated. We introduce a unified notation and taxonomy of adversarial attacks on explanations. Adversarial examples, data poisoning, and backdoor attacks are key safety issues in XAI. Defense methods like model regularization improve the robustness of explanations. We outline the emerging research directions in adversarial XAI.
Software: survex
 survex: an R package for explaining machine learning survival models
survex: an R package for explaining machine learning survival models
Mikołaj Spytek, Mateusz Krzyziński, Sophie Hanna Langbein, Hubert Baniecki, Marvin N Wright, Przemysław Biecek
Bioinformatics (2023)
This paper demonstrates the functionalities of the survex package, which provides a comprehensive set of tools for explaining machine learning survival models. The capabilities of the proposed software encompass understanding and diagnosing survival models, which can lead to their improvement. By revealing insights into the decision-making process, such as variable effects and importances, survex enables the assessment of model reliability and the detection of biases. Thus, promoting transparency and responsibility in sensitive areas.
SurvSHAP(t)
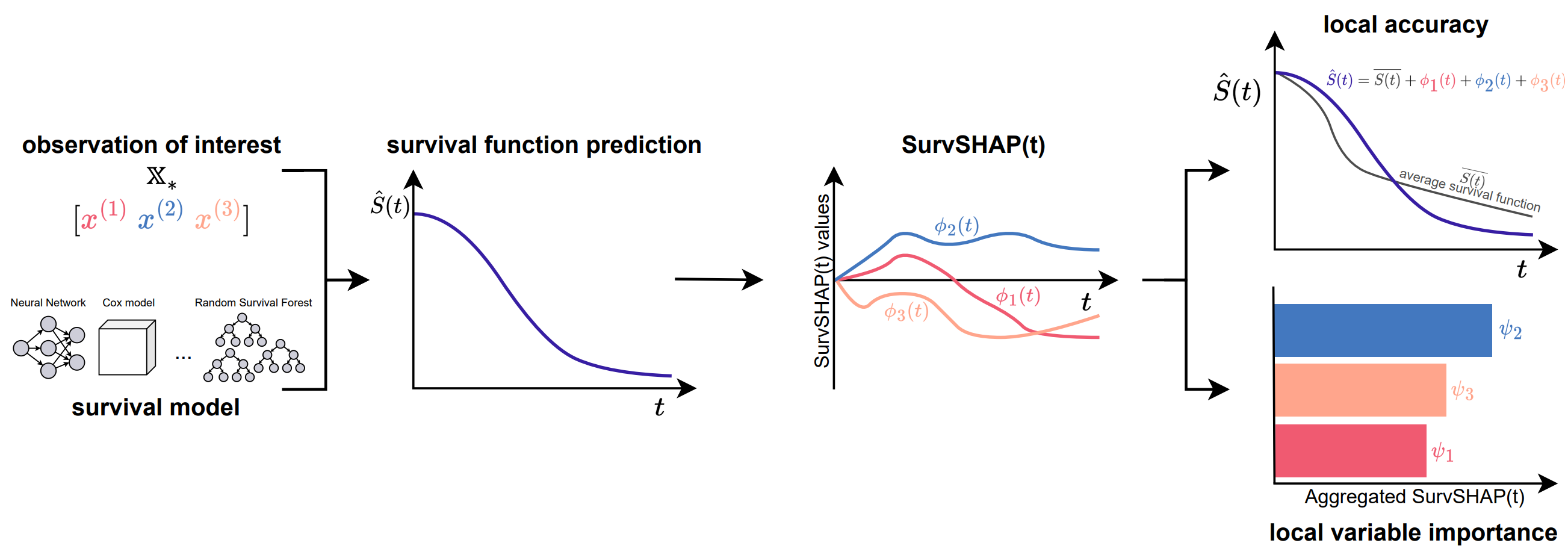 SurvSHAP(t): Time-dependent explanations of machine learning survival models
SurvSHAP(t): Time-dependent explanations of machine learning survival models
Mateusz Krzyziński, Mikołaj Spytek, Hubert Baniecki, Przemysław Biecek
Knowledge-Based Systems (2023)
In this paper, we introduce SurvSHAP(t), the first time-dependent explanation that allows for interpreting survival black-box models. The proposed methods aim to enhance precision diagnostics and support domain experts in making decisions. SurvSHAP(t) is model-agnostic and can be applied to all models with functional output. We provide an accessible implementation of time-dependent explanations in Python at this URL.
IEMA
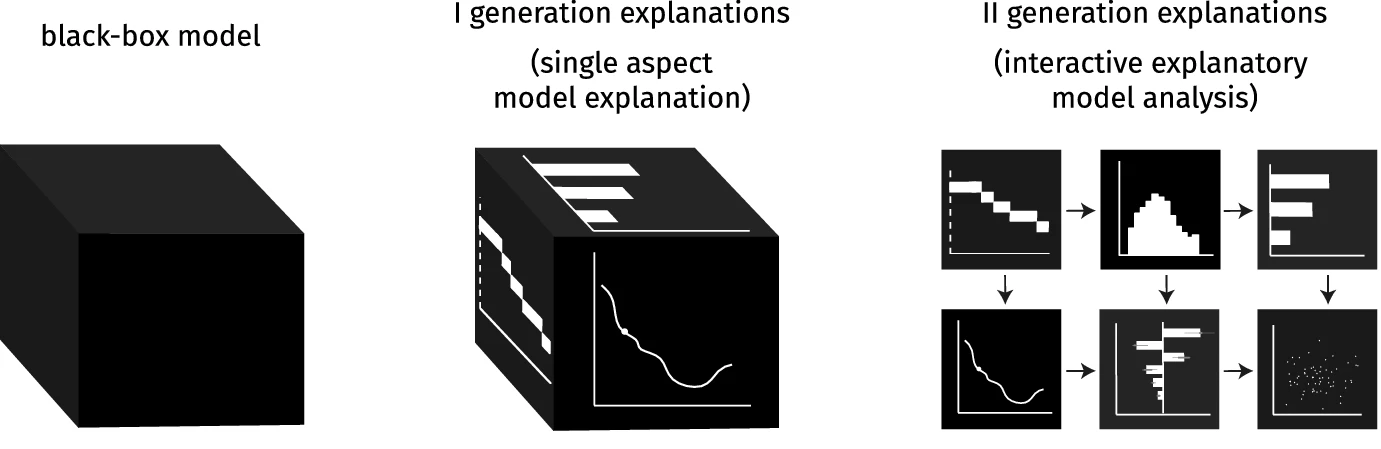 The grammar of interactive explanatory model analysis
The grammar of interactive explanatory model analysis
Hubert Baniecki, Dariusz Parzych, Przemyslaw Biecek
Data Mining and Knowledge Discovery (2023)
This paper proposes how different Explanatory Model Analysis (EMA) methods complement each other and discusses why it is essential to juxtapose them. The introduced process of Interactive EMA (IEMA) derives from the algorithmic side of explainable machine learning and aims to embrace ideas developed in cognitive sciences. We formalize the grammar of IEMA to describe human-model interaction. We conduct a user study to evaluate the usefulness of IEMA, which indicates that an interactive sequential analysis of a model may increase the accuracy and confidence of human decision making.
Software: fairmodels
 fairmodels: a Flexible Tool for Bias Detection, Visualization, and Mitigation in Binary Classification Models
fairmodels: a Flexible Tool for Bias Detection, Visualization, and Mitigation in Binary Classification Models
Jakub Wiśniewski, Przemyslaw Biecek
The R Journal (2022)
This article introduces an R package fairmodels that helps to validate fairness and eliminate bias in binary classification models quickly and flexibly. It offers a model-agnostic approach to bias detection, visualization, and mitigation. The implemented functions and fairness metrics enable model fairness validation from different perspectives. In addition, the package includes a series of methods for bias mitigation that aim to diminish the discrimination in the model. The package is designed to examine a single model and facilitate comparisons between multiple models.
Fooling PDP
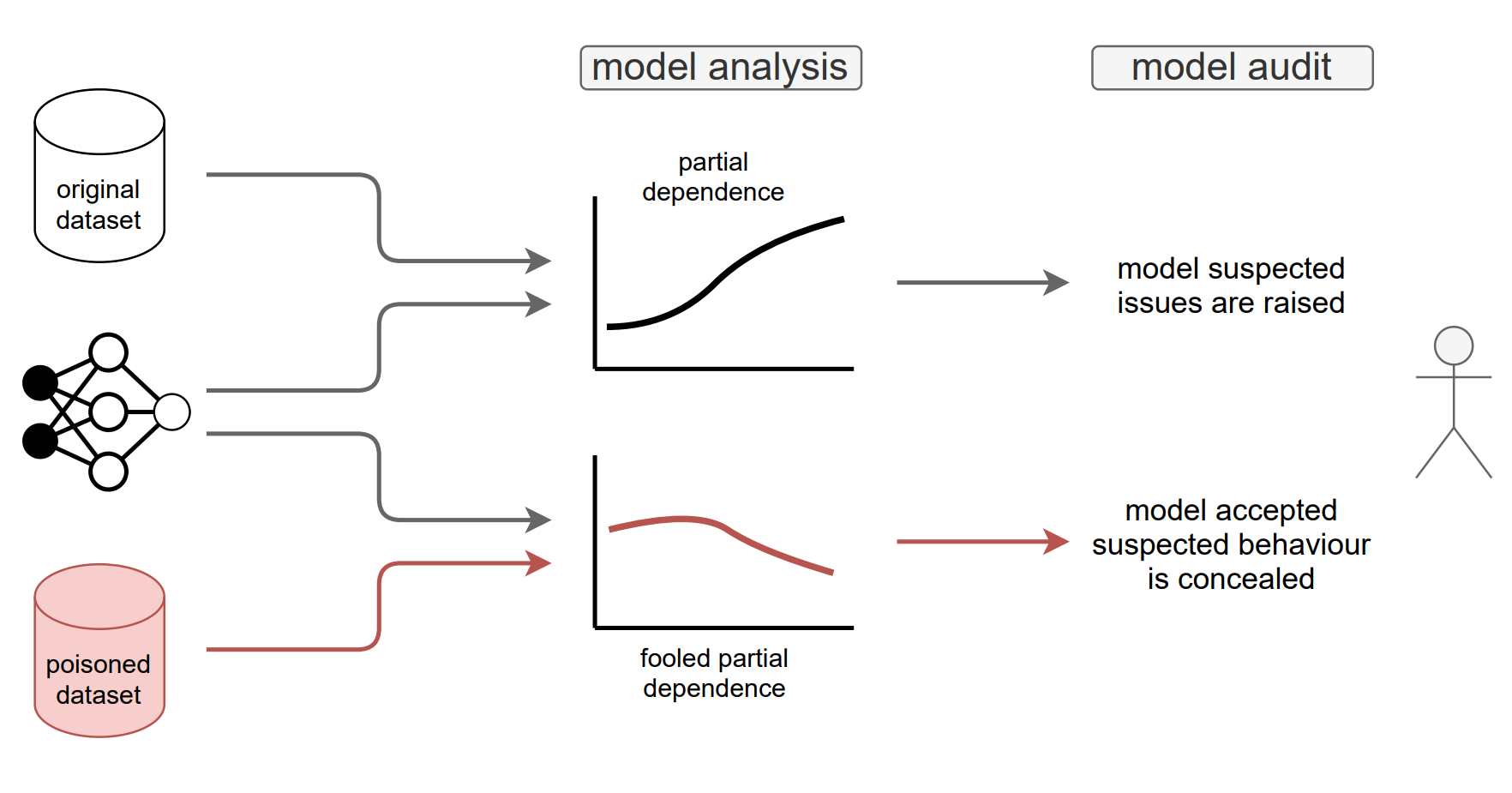 Fooling Partial Dependence via Data Poisoning
Fooling Partial Dependence via Data Poisoning
Hubert Baniecki, Wojciech Kretowicz, Przemyslaw Biecek
ECML PKDD (2022)
We showcase that PD can be manipulated in an adversarial manner, which is alarming, especially in financial or medical applications where auditability became a must-have trait supporting black-box machine learning. The fooling is performed via poisoning the data to bend and shift explanations in the desired direction using genetic and gradient algorithms.
Fooling SHAP
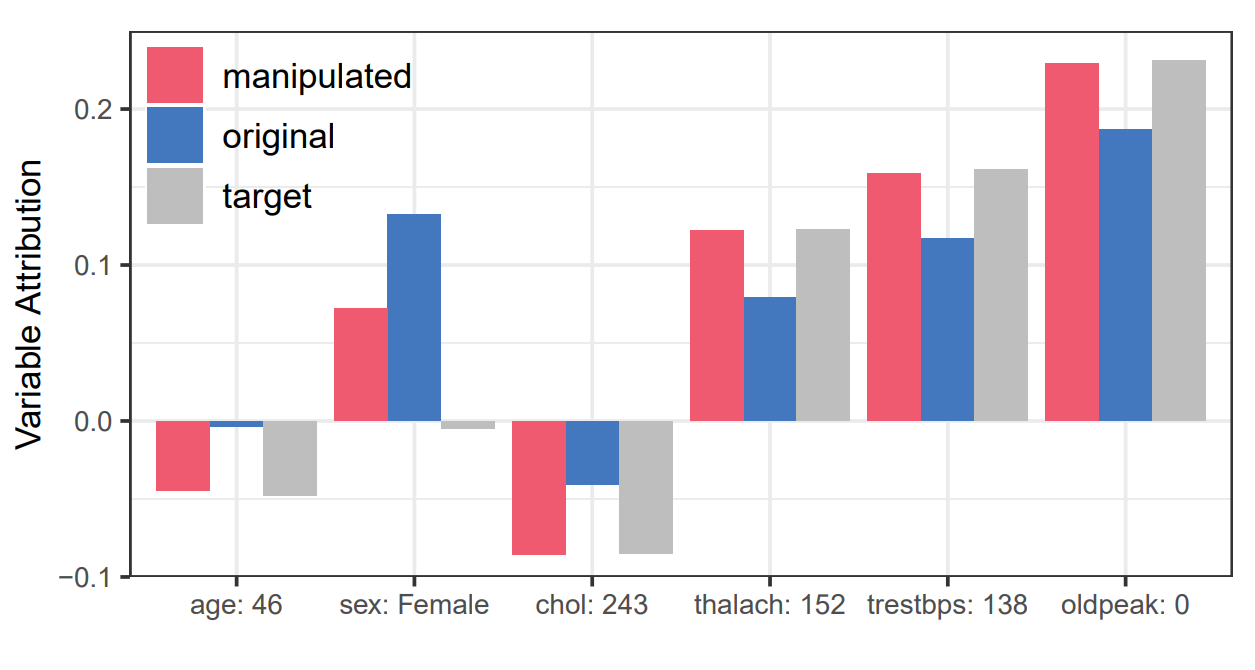 Manipulating SHAP via Adversarial Data Perturbations (Student Abstract)
Manipulating SHAP via Adversarial Data Perturbations (Student Abstract)
Hubert Baniecki, Przemyslaw Biecek
AAAI Conference on Artificial Intelligence (2022)
We introduce a model-agnostic algorithm for manipulating SHapley Additive exPlanations (SHAP) with perturbation of tabular data. It is evaluated on predictive tasks from healthcare and financial domains to illustrate how crucial is the context of data distribution in interpreting machine learning models. Our method supports checking the stability of the explanations used by various stakeholders apparent in the domain of responsible AI; moreover, the result highlights the explanations’ vulnerability that can be exploited by an adversary.
Models in the Wild
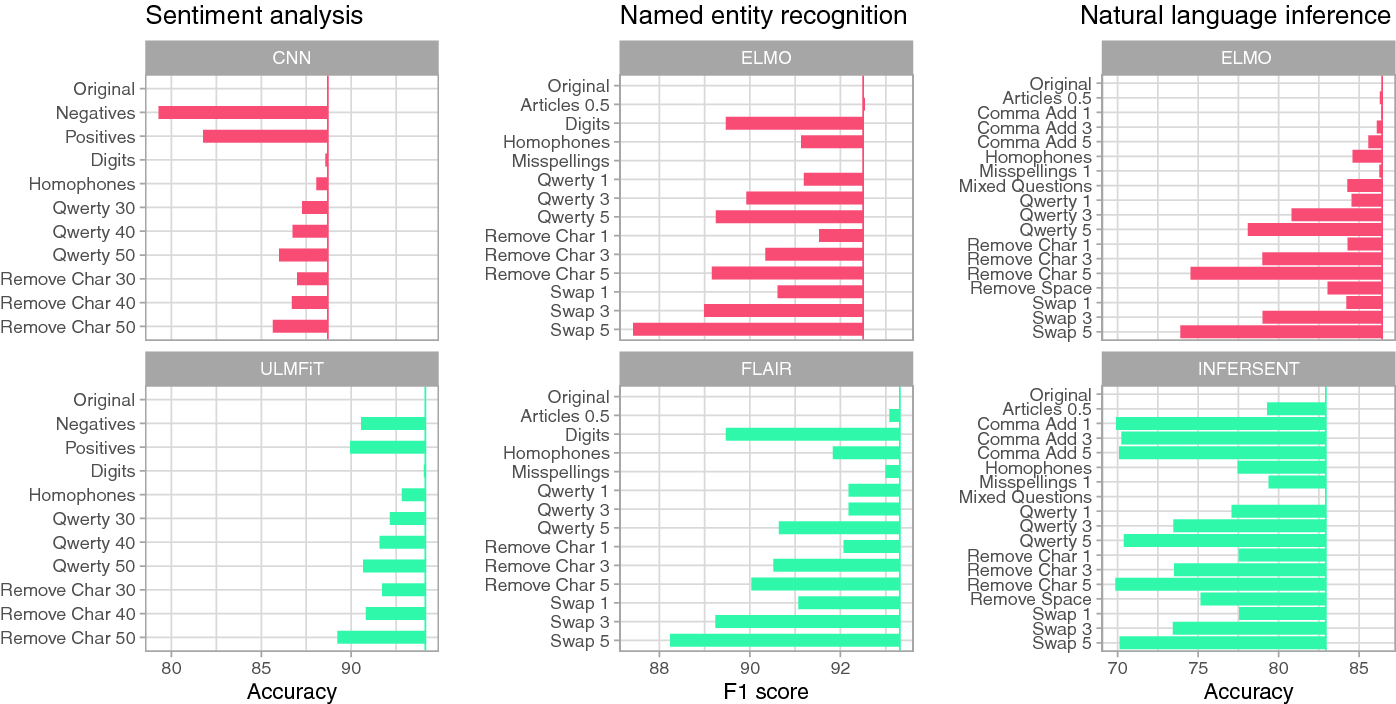 Models in the Wild: On Corruption Robustness of Neural NLP Systems
Models in the Wild: On Corruption Robustness of Neural NLP Systems
Barbara Rychalska, Dominika Basaj, Alicja Gosiewska, Przemyslaw Biecek
International Conference on Neural Information Processing (2019)
In this paper we introduce WildNLP - a framework for testing model stability in a natural setting where text corruptions such as keyboard errors or misspelling occur. We compare robustness of deep learning models from 4 popular NLP tasks: Q&A, NLI, NER and Sentiment Analysis by testing their performance on aspects introduced in the framework. In particular, we focus on a comparison between recent state-of-the-art text representations and non-contextualized word embeddings. In order to improve robustness, we perform adversarial training on selected aspects and check its transferability to the improvement of models with various corruption types. We find that the high performance of models does not ensure sufficient robustness, although modern embedding techniques help to improve it.
Software: auditor
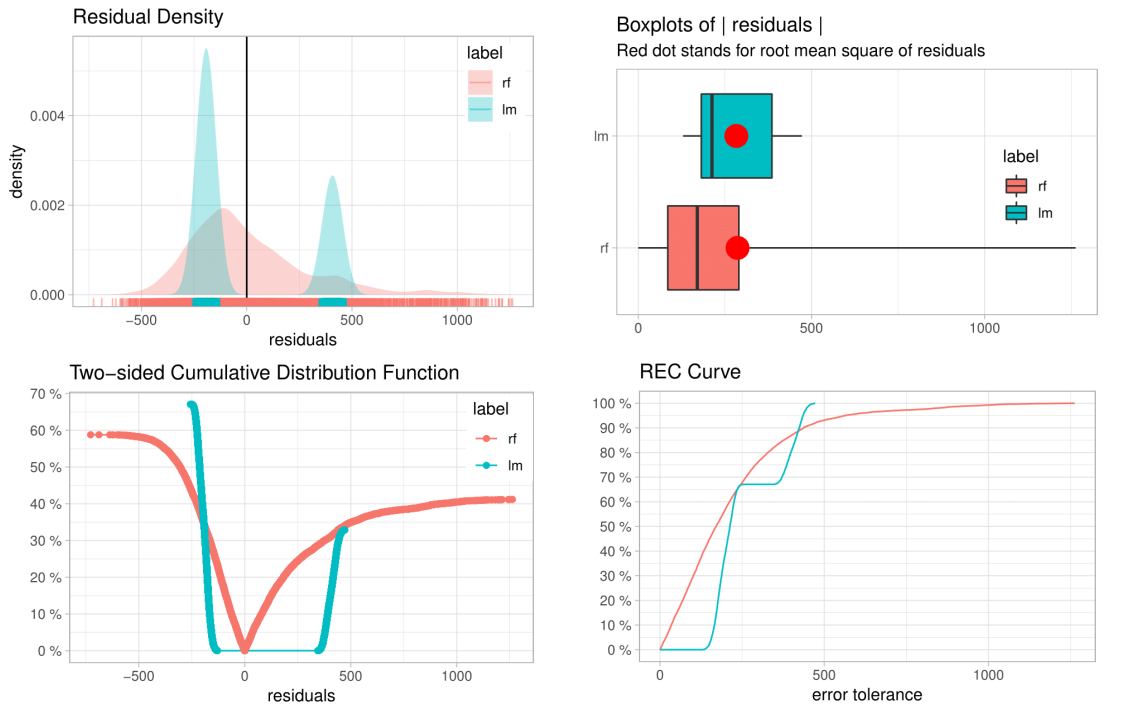 auditor: an R Package for Model-Agnostic Visual Validation and Diagnostics
auditor: an R Package for Model-Agnostic Visual Validation and Diagnostics
Alicja Gosiewska, Przemyslaw Biecek
The R Journal (2019)
This paper describes methodology and tools for model-agnostic auditing. It provides functinos for assessing and comparing the goodness of fit and performance of models. In addition, the package may be used for analysis of the similarity of residuals and for identification of outliers and influential observations. The examination is carried out by diagnostic scores and visual verification. The code presented in this paper are implemented in the auditor package. Its flexible and consistent grammar facilitates the validation models of a large class of models.